graph LR
A[Load CSV] --> B[(Database)];
H[/CSV 1/] --> A
I[/CSV 2/] --> A
D[Calculate todays date] --> E[[Run SQL Script]]
K[Get todays date manual/config]:::manual --> E
J{Is todays date provided?} -->|no| D
J -->|yes| K
B --> E
E --> F[Generate Excel output]
F --> G[/Excel Output/]
classDef manual fill:#FFCCCC
Session 2: Deeper dive into key components
Overview
Unlike the first class that aimed to introduce RAP and why it was relevant, the purposes of this class is to show in more detail what each principle is, plus some practical examples of how to apply this. Or in other words - show How to RAP. This page thus has the slides that are used in the in-person training, as well as examples to refer to
Recording of the training
A recording of the session is available on the Notion site. Scroll down to “Day 2” of the “In-person course” section and expand the “Video Recording” sub-section.
Presentation for the session
Practical content
To support the in-person training, below we list out the supporting material that learners can refer to. It outlines each of the principles in high level, and some in more detail where technical examples are valuable. See the NHS site on RAP for more details on each principle.
Practical content, first set
Principle 1: Automation
As the fundamental principles of RAP is to make the process of (in our case) making official statistics reproducible, we should do our utmost to eliminate manual human steps (unless they are explicitly needed off course!). Thus we want to create a script that automates the whole process and creates a very neat handoff of a tidy data file as output. A key aspect here is mapping the process so that your script can operate in a way as to minimize human actions.
In our case, we’ve seen this with the overall process of the price statistics pipeline with web scraped data, as well as the specific step that maps the process of web scraping.
We’ll see some practical steps below (once we’ve covered modular coding) on how that could work in practice.
Principle 2: Modular, re-usable
Modularity and coupling are two very critical aspects and we should spend time discussing them in detail. They actually are conceptually quite related and for simplicity (in this course), we can consider them as trying to achieve the same thing. These are also both far from a RAP (or even official statistics concept) as they are widely discussed in the wider software engineering and even software architecture! This should not discourage us though - as knowing these is also important for us for two aspects:
- It helps us write better code when we are developing pipelines, and
- It also helps us design more dynamic overall processes of how we build operational flows with alternative data.
So what is the concept?
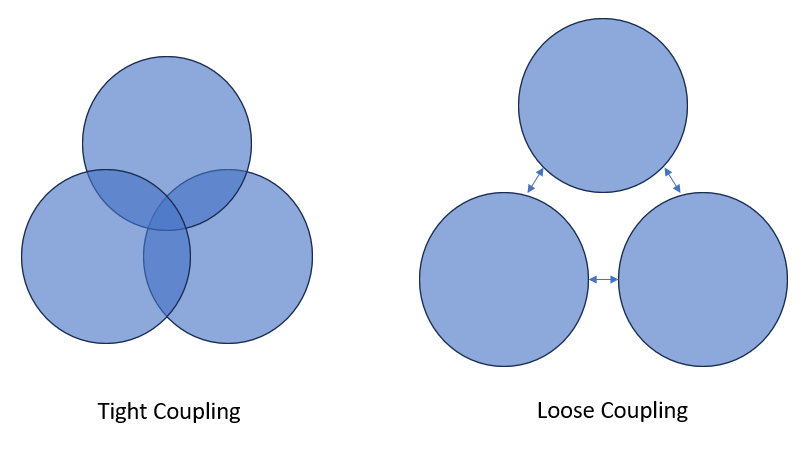
If we write everything all in one long and big script - it is likely that some small thing will break the script and we will have to spend a long time figuring out what is wrong and fixing it. However, if we isolate specific logical steps into functions and then put them together - if something happens, then we will quickly be able to isolate it to the affected function and fix that function. Each function is thus meant to do just one thing - but it does that one thing very well!
We should thus aim to develop loosely coupled software.
Furthermore, we can also apply this thinking to bigger processes as we saw when we mapped the overall process of the price statistics pipeline with web scraped data - we broke out the overall process into several steps - in essence separate pipelines.
What does this mean if we put it together?
Lets see what this means by focusing on the example provided by the NHS - what could this look like in code?
Remember the visual demo from the RAP guide (repeated here):
Let’s see what general functions could be created
def load_csv():
# do something to load the csv and convert it to a clean dataframe
return dataframe
def load_database(dataframe):
# load the data in the dataframe into the database
def output_date_for_processing(optional_date_input):
# check if the input data is provided, if not, calculate it
return todays_date
def run_sql_script(todays_date):
# Run the SQL script that we need to run
return dataframe_output
def save_excel_output(dataframe, location_to_save_output):
# Save the output in the location we wantNow we can figure out how to automate this. A very simple way when you are starting out is to make one main() function that calls other functions, and then give inputs to that function for it to operate properly:
def main(csv_to_load_into_the_database, date, location_to_save_output):
# main function that operationalizes everything
# Step 1:
# load the csv
dataframe = load_csv(csv_to_load_into_the_database)
# save the data into the databse
load_database(dataframe)
# Step 2:
# check date
date_to_use = output_date_for_processing(date)
# send this to SQL script
dataframe_from_sql = run_sql_script(date_to_use)
# save this output
save_excel_output(dataframe_from_sql)
# -----------------------------------------------------------------------
csv1 = "C:/some/file/path/file.csv"
todays_date = '2024-09-18'
location_to_save = "C:/some/other/path"
# lets call the main function
main(csv1, todays_date, location_to_save)To better understand how this works for a scraper - we can also walk through first the demo web scraper of a public scraping site, and then how to make this scraper RAP friendly.
That’s it! Check out a helpful article by the NHS on functional programming for a slighly deper dive.
Exercise 1
Ready to try this yourself? Look at a notebook that you developed for this course - and see how to separate out what you did into functions. Talk to the mentors in the room if you have questions!
Practical content, second set
Principle 3: Transparency
Working in a transparent manner (even if in your NSO this will apply to a more internal audience rather than publicly), is very useful as it helps develops skills and a way of working that results in better code and hence easier (and more reproducible) processes. This principle actually links quite heavily with several other principles such as:
- use of a git based version control software to store an authoritative version of the code and all related aspects (this does not have to be GitHub, GitLab for example is also very popular);
- using open-source tools (principle 4)
- adopting good development practices (which includes good coding practices and also documentation of how the code works) (principle 6)
- and others!
While at a glance, this principle seems to be repeated in other principles - however transparency stands as a principle on its own. Adopting all other principles but still working in a non-transparent manner will naturally result in lower trust (as noone will know how the specific process works), lower levels of collaboration (and thus higher likelihood that mistakes or improvements will be identified), and a very strong likelihood of isolation from consistent standards others have adopted. Thus working in a transparent manner (as much as possible in your NSO) is very useful and helps push the pipeline to be even more mature and reproducible!
Principle 4: Use of open-source tools
As RAP fundamentally is about reproducibility and technical maturity - both aspects are most effectively enabled if open-source tools are used. Open-source tools (like python or R) are incredibly popular around the world - hence there is lots of training on the topic, ChatGPT will give you a good response for specific problems, and its more likely that your colleagues can learn it (or have already) and can help you develop the pipeline or peer review it!
As an aside - several organizations (for example see IEEE specturm and Statista) rate the top programming languages around the world and Python (R less so but still a bit) usually are rated highly. The challenge with these surveys is they assess or survey all developers - and some developers need to focus on back-end (SQL or Java) or web development (hence JavaScript) - which can seem misleading. A good takeaway is that for dynamic and simple languages for data analysis and processing - Python and R are very popular - which helps when you are developing your pipeline!
Principle 5: Version control
RAPs (and code that helps create official statistics) if fundamentally well developed open-sources software. Hence we need to adopt tools that help us manage all the aspects of its lifecycle - and git based version control with a site like GitHub or GitLab is the most popular way to help develop and operates software. As a summary it allows you to:
- version control all your code and documents (and data too for non-confidential data) - thus you never have to know which is the final one or which was used when in the past!
- have a look at the commits to the
mainbranch of this repo!
- have a look at the commits to the
- furthemore, from a development point of view, you can also create targeted releases for stable versions and see what the release was at that time - making it very easy to know what version of the pipeline was used historically!
- have a look at the releases for the python
pandaslibrary, very popular with data analysis package!
- have a look at the releases for the python
- create different code bases (as braches) off the main one that allow you to collaborate with others or develop/fix parts simultaneously, as well as join them all together when appropriate;
- for example, have a look at a pull request (a request to merge one branch into the main branch) that we collaborated on for this class - where you can have one individual review the change and approve it prior to the change happening!
- project manage all the aspects of the work by creating issues (for each task or bug), milestones (for phases or categories of the work).
- check out the GitHub project we used to coordinate the development of materials for this class!
- automate testing and deployment of your package or its related aspects automatically (an advanced feature but quite useful).
- and many more!
We covered git and GitHub/Lab in detail in the slides (above), however for more details, feel free to check out the NHS intro to Git for more details.
Exercise 2 (on your own)
Ready to try this yourself? Let’s try to create a very simple GitHub repository. To walkthrough this excersize, you need to have git installed on your computer and you need a GitHub account. Do these steps first if you don’t already have this.
There are several exercises we recommend you try at your own pace. As these may take some time, this can be done in the afternoon:
- GitHub has a very very simple Hello World example - https://docs.github.com/en/get-started/start-your-journey/hello-world. Follow that to create a repository!
- As the above example did not have a copy of the code locally, a slightly more involved walkthrough is available from the NHS RAP community of practice on committing work to a remote repository.
- The NHS RAP Community of Practice also has a walkthrough on how to work with branches
Practical content, third set
Now we are in the home stretch! We are starting to see how we can make better software (i.e. the RAP way), but there are three more principles to go!
Principle 6: Good development practices
There are a few good practices that you should adopt when you develop:
When you start out, map your process so that the code is well defined and logical. We covered this in the first principle, however its applicable to good development practices as well designed code will be clear! It will thus help any colleagues looking (or reviewing) at the code (soon or later in the future), but it will also help you as it will be much easier to understand what is going on;
Document your code and the overall process the RAP is automating! The RAP way (and the way of all good open-source code) is that the documentation is quite often embedded into the repository where the code is and is part of the delivery. Thus if the code or process changes, the documentation is updated. For example, the RAP Companion exemplar package contains all the key components (the code (i.e. functions), tests (we will cover this later), documentation, and the data (if its not confidential)):
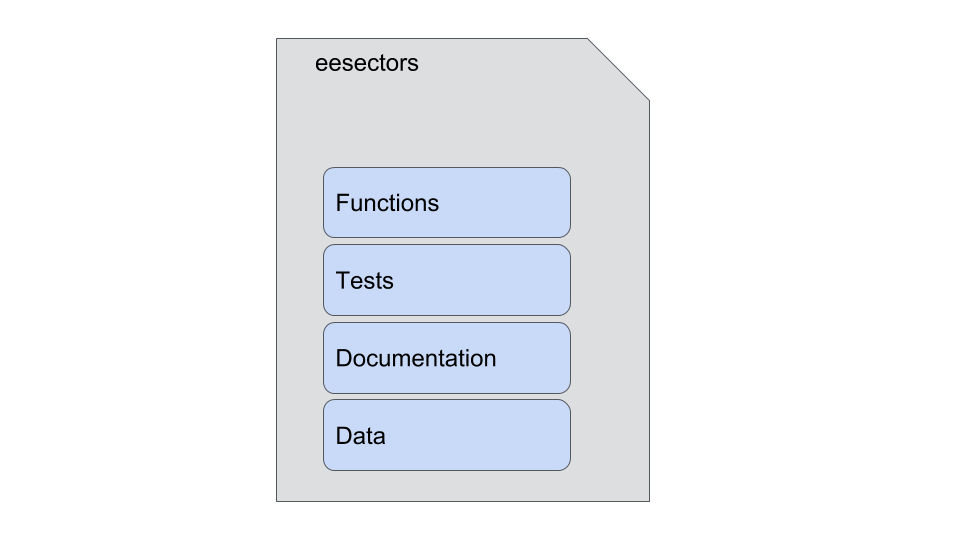
The process map you developed can thus be embedded into this documentation and be useful to anyone!
For instance for this class (as its a repository) stores all docs as
qmdfiles (which are a type of quarto markup file that renders into the beautiful html site byquarto). Have a look at the raw documentation here - https://github.com/sergegoussev/ESCAP_RAP_class/tree/main/docsSet up a virtual environment and clarify the dependencies for the code. As open-source code can be very dispersed and it is up to the developer to choose what they find most applicable. This can mean different versions of python (3.10 or 3.7 for example), different python libraries (and their different versions), etc. This can quickly become a nightmare and make it near impossible to reproduce (and often times even run) someone else’s code - known colloquially as dependency hell. There are however ways to solve this problem by:
- Not installing all your code into your main installation and working version of python, but by creating a simple and lean version just for the code you are developing. Python for your RAP package thus runs out of this lean environment, called a virtual environment. Check out more about why you should use virtual environments and what types there are.
- Indlude in your repository a clear guide of how to recreate your virtual environment. Popular solutions are creating a
reqirements.txt, or specifying a conda environmentyml(a popular environment manager). See the environment.yml for this repository as an example.
Use
pyfiles to store your production pipeline and an Integrated Development Environemnt (IDE) such as VS Code, not ajupyter notebook. This follows from principle 2 (modular code) as we can then group the functions by theme and put them in separate.pyfiles - which keeps your code logical and clear. A way this could be considered is converting the whole pipeline into a package (likeBeautifulSouporrequeststhat we used to learn how to scrape!)- Check out this guide on packaging python code to make it a package.
Use logging instead of
print(). When we first start out and especially in a jupyter notebook - we useprint()a lot to see what is going on, especially when the logic is complex. However when we create a production pipeline - we still want to know about many of these scenarios (like something that happened). However we should notprint()the statement as it is very hard to read and later analyze the example. Instead we can save all that in a light.logfile- Check out the guide on logging by the NHS RAP site
Anticipate and handle errors. Sometimes something unanticipated happens (you probably encountered lots of cases during development in this web scraping course) - which causes your script to crash or error out. This will likely happen when your pipeline runs, but by anticipating this, you can handle the situations gracefully. For instance we may not want the script to crash but just log that something unanticipated happened. Or we may want the process to stop but the error we want to occur should be very clear and explicit about what went wrong!
- Check out this guide on error handling by the NHS RAP site
We covered functional programming above - but further to this, you can include documentation for what each function does. For example we have a function that scrapes a site. We can very clearly document how the function works, what it expects as an input, what it returns as an output:
def scrape_url( url: str, header: dict, session: requests.sessions.Session, logger: logging.Logger) -> BeautifulSoup: """ Scrapes a specific URL and logs that the site was scraped. Takes the input temperature (in Fahrenheit), calculates the value of the same temperature in Celsius, and then returns this value. Args: url: a string representing the url to scrape header: a header dictionary to include with the request to the site session: the python requests session being used to make the call (for memory optimization) logger: a logging object so that the fact that we called the site can be recorded Returns: A Beautiful Soup object that you can work with """ with session.get(url, headers=header) as res: response = BeautifulSoup(res.text, "html.parser") logger.info("Scraped {url}".format(url=url)) return responseThis makes it very easy for others (and yourself later too) to use code that is well documented and modular!
And many more best practices that you can learn slowly and at your pace! Have a look at the Python page (NHS source again) to see some good practices features.
Principle 7: Testing
Once you’ve converted your code into functions, it is best to create test data and test that the function works exactly as you expect. This is a very useful step as this makes you very certain that all your functions work exactly as expected - meaning that your entire pipeline works as expected. This process should also be automated - which allows you to check the code every time you make a change. If your code doesn’t pass the tests you set out for it - then you can stop short of using it in production and go and fix it!
Testing is a complex topic - so we won’t cover it in more detail. However we encourage you to check out the unit testing guide on the NHS RAP site.
Principle 8: Peer review
Peer review is a very powerful and useful way to ensure that the package works as expected, make improvements, or even work collaboratively! We can do it in several ways, but the Pull request feature is an easy and natural place to do peer review as it allows you to assign reviewers and assignee (say the reviewer needs to approve) the change. It also shows you that peer review is valuable for any change to the pipeline - i.e. it is not something you do once at the end of development. For example:
You may want to propose something and have your colleague validate the proposed change or modify it as necessary - before it is accepted. For instance when we were developing this training materials, we used the pull request feature to review major proposed chagnes - such as the scope of the course!
You may want to have someone review the code to ensure the code is good and it is improving (you never want to have your code deteriorate over time - its instead always good to aim to constantly improve the code). You can also share knowledge as different colleagues with different levels of skills review the code to collaborate and also to share skills. The NHS RAP site, as well as Google’s change log (i.e. every change) guide are great resources to check out on this topic!
Exercise 3
Ready to try this out? Do one of two possible exercises:
Exercise 3.1. Peer review exercise
If you have a GitHub repo set up and have walked through the above examples (exercise 2), find someone else who has done the same. Steps to follow:
- Create a branch, push changes to that branch, and then create a Pull Request to merge this branch into the main one.
- Assign your collaborator on the repo (you may need to add the person you are working with as a collaborator to the repo - make the change in Settings > Collaborators) to the request.
- Your partner will review and approve the change
- You can then merge the change into main
Resources:
- The guide on Pull and Merge requests by the NHS RAP Community of Practice will walk through how to create and push pull requesets.
Exercise 3.2. Add doc strings to the functions you created in exercise 1
Wrap up
While we’ve covered the main principles of RAP above - it may feel like it will take you a long time to get all this. However, you can start out small and adopt RAP gradually. Indeed, RAP can be seen as a gradual progression along 3 levels:
- Bronze or baseline RAP - you have adopted some best practices
- Silver - you are now implementing many good practices and your RAP is increasingly mature, reproducible, and effective
- Gold - you have reached a level of easy reproducibility and mature code
Check out the RAP levels on the NHS site for more info of what is in each level.
Bronze is quite a nice starting place, however as you keep progressing, you can gradually adopt features from the silver (or even gold) level - as not all aspects of a specific level need to be adopted all at once!